그룹함수는 수많은 열이 있는 데이터를 축소 - 그룹화 하는 함수를 의미한다.
기본적인 그룹함수는 다음과 같다.
| COUNT | 입력되는 데이터의 총 건수를 출력 |
| SUM | 입력된 데이터의 합 출력 |
| AVG | 입력된 데이터의 평균 출력 |
| MAX | 입력된 데이터 중 최대값 출력 |
| MIN | 입력된 데이터 중 최소값 출력 |
또한 그룹함수끼리 비교연산하는 분석함수가 있다.
| ROLLUP | 입력되는 데이터의 소계를 출력 |
| PIVOT | 특정 열의 값을 행으로 묶어 출력 |
| LAG | 지정된 값만큼 열을 내려서 출력 |
| RANK | 데이터의 순위를 나타내서 출력 |
데이터는 많은 행으로 이루어져 있다.

이런 많은 값의 데이터들을 하나로 합쳐주는 예시를 보자.
1. COUNT()
CONUT 함수는 입력된 데이터가 총 몇개인지 세어주는 함수이다.
select count(ENAME)
from EMP;

무수히 많았던 행이 하나로 합쳐친 것이 보인다.
입력된 ENAME의 갯수가 14개이므로, 14를 출력해서 하나의 행이 되었다.
2. MAX(), MIN()
MAX, MIN 함수는 입력된 데이터의 가장 큰 값과 작은 값을 보여주는 함수이다.
select MAX(SAL)
from EMP;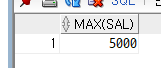
select MIN(SAL)
from EMP;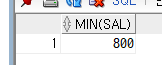
다음과 같이 최소값과 최대값, 하나만 출력하면서 행이 하나로 합쳐졌다.
3. AVG()
AVG함수는 입력된 데이터의 평균을 구해준다.
select avg(height)
from student;
4. SUM()
SUM함수는 입력된 데이터의 합을 구해준다.
select SUM(P_QTY)
from PANMAE;
-SUB QUERY
괄호 속의 또 다른 괄호를 넣어 만드는 함수를 SUB QUERY라고 한다.
서브쿼리는 SELECT, FROM, WHERE절 어디에도 들어갈 수 있으며, 조건을 세부화 하거나 새로운 행을 붙여 새로운 가상 테이블을 만드는 등 다양한 방법으로 사용할 수 있다.
예시를 보자.
앞서 MAX 값을 구할 때, 우리는 EMP 테이블의 SAL 이 5000임을 확인했다.
이를 서브쿼리 없이 만들면,
select MAX(SAL)
from EMP;
select *
from EMP
where SAL=5000;이렇게 총 두 번의 실행을 거쳐야만한다. 그러나, 서브쿼리를 넣어 진행하면
select *
from EMP
where SAL=(select MAX(SAL) from EMP); 다음과 같이 한번의 실행으로도 같은 값을 구할 수 있다.
단지, 서브쿼리를 진행할 때 주의할 점은 그룹함수를 넣을 때 행의 갯수가 반드시 맞아야만한다는 점이다.
-GROUP BY
그룹함수를 구할 때, 전체 데이터 값을 조회하는 것이 아니라, 특정 조건을 주고 해당 조건을 찾게 하는 것이 연산 속도에 훨씬 이득이 되며, 찾기도 쉬워지며, 데이터가 구체화된다.
다음 예시를 보자.
select MAX(sal)
from emp; 다음과 같은 함수는 전체 값을 구할수는 있지만, 조금 더 세부적으로.. 예를 들면 부서 별 전체 급여의 값을 구하거나 할 수 없다. 부서별~ 직업별~ 같이 부서나, 직업과 같은 것을 그룹으로 묶어 그 그룹의 최대값을 구함으로서 데이터가 구체화 된다.
select MAX(sal), deptno
from emp
group by deptno;
위의 예시를 보면 알 수 있듯 GROUP BY 절은 정렬을 지원하지 않기 때문에, 정렬을 필요로 한다면, 추가로 ORDER BY 절을 입력해야한다.
select sum(sal), deptno
from emp
group by deptno
order by deptno;
-HAVING 절
그룹화 되지 않은 데이터의 조건을 조회할 때는 WHERE 절을 이용했다.
그러나 그룹화 된 절은 HAVING 절을 이용해야 한다. 왜 그럴까?
데이터를 조회할 때는 6개의 절을 이용한다. 이 절을 읽어들이는 순서는 다음과 같다
⑤SELECT
①FROM
②WHERE
③GROUP
④HAVING
⑥ORDER
다음과 같기 때문에 WHERE은 표를 불러오고 바로 조건을 제한하지만 HAVING은 그룹화 후 그 그룹에 대해서 조건을 제한한다. 그렇기 때문에 연산이 훨씬 줄어드는데다가, WHERE절을 이용할 경우 오류가 걸리거나 데이터가 출력되지 않을 수 있다.
select deptno, avg(nvl(sal,0))
from emp
WHERE avg(nvl(sal,0))>2000
group by deptno;
그룹함수에 WHERE 절을 사용하면 다음과 같은 오류문구가 출력된다. 문법상, GROUP를 아래로 내리고 WHERE은 HAVING으로 바꿔보자.
select deptno, avg(nvl(sal,0))
from emp
group by deptno
having avg(nvl(sal,0))>2000;
다음과 같이 HAVING을 이용해야만 올바른 값을 얻을 수 있음을 볼 수 있다.
5. ROLLUP()
ROLLUP 함수는 데이터의 합계를 구해주는 분석함수이다.
예를 들어보자. 만일 부서 내 직업 간 급여의 평균을 구하는 방법을 생각해보자.
일반적인 그룹함수들을 엮으려고 했다면, 부사간 급여, 직업간 급여, 전체 급여를 따로따로 구해서 합치는 방법밖에는 없을 것이다.
select deptno, Null job, ROUND(AVG(sal),1) avg_sal,count(*)cnt_emp
from emp
group by deptno
union all
select deptno, job, ROUND(AVG(SAL),1) avg_sal,count(*)cnt_emp
from emp
group by deptno,job
union all
select null deptno, Null job, ROUND(AVG(SAL),1) avg_sal,count(*)cnt_emp
from emp
order by deptno,job;
다음과 같은 긴 코드를, ROLLUP 함수만 있으면 쉽게 구현 가능하다.
select deptno,job,ROUND(AVG(SAL),1) avg_sal,count(*)cnt_emp
from emp
group by rollup(deptno,job);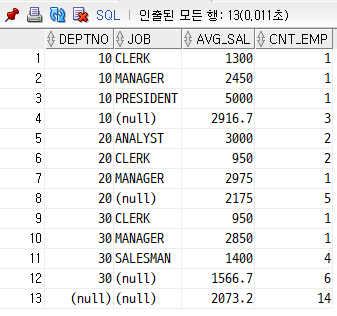
다음과 같이 추가되는 걸 볼 수 있다.
ROLLUP 함수의 원리는 다음과 같다
①GROUP BY
②컬럼 1 소계
③컬럼1+컬럼2 소계
④전체 소계
다음과 같이 작용하기 때문에 묶인 컬럼 사이사이마다 소계가 들어가게 된다.
6. PIVOT()
PIVOT은 특정 열의 함수를 행으로 올리는 기법이다.
예를 들어보자.
SELECT POSITION, AVG(PAY)
FROM PROFESSOR
GROUP BY POSITION;
다음과 같은 데이터가 있다고 가정하자. 이 데이터 중 POSITION 부분을 행으로 올려달라는 요청을 받았다. 이를 어떻게 할까?
DECODE함수를 이용하여 정교수 쪽엔 정교수 데이터만, 조교수 데이터는 조교수만 남겨보자.
SELECT
DECODE(POSITION,'정교수',PAY) "정교수",
DECODE(POSITION,'조교수',PAY) "조교수",
DECODE(POSITION,'전임강사',PAY) "전임강사"
FROM PROFESSOR;POSITION에 '정교수' 라는 데이터를 만나면 정교수 부분에 PAY를 출력하고, '조교수' 라는 데이터를 만나면 조교수 부분에 PAY를 출력하고, '전임강사' 라는 데이터를 만나면 전임강사 부분에 PAY를 출력하도록 DECODE 함수를 코딩해보자.

이제, 이 함수들을 그룹함수로 묶어보자. AVG함수를 이용하여 묶으면 NULL 값을 제외한 모든 값들의 평균치를 구할 수 있다. (ROUND함수는 조교수 평균이 지저분해서 썼음)
SELECT
ROUND(AVG(DECODE(POSITION,'정교수',PAY))) "정교수",
ROUND(AVG(DECODE(POSITION,'조교수',PAY))) "조교수",
ROUND(AVG(DECODE(POSITION,'전임강사',PAY))) "전임강사"
FROM PROFESSOR;
이것을 DECODE 를 사용하지 않고 PIVOT 함수로만 나타낼 수 있는데,
SELECT *
FROM (SELECT POSITION, PAY FROM PROFESSOR)
PIVOT
(
AVG(PAY) FOR POSITION IN
(
'정교수' AS "정교수",
'조교수' AS "조교수",
'전임강사' AS "전임강사"
)
);
다음과 같이 나타낼 수도 있다.
(근데 DECODE가 좀 더 편해보이긴 한다)
6. LAG()
LAG 함수는 지정값만큼 열을 내려서 출력하는 함수이다.
문법: LAG(컬럼명, OFFSET, 기본 출력값) OVER (정렬할 컬럼)
OFFSET은 얼마나 열을 밀어낼것인지, 기본 출력값은 밀려난 열에 어떤 값을 집어넣을지 결정한다.
예를 들어보자.
select ENAME, SAL, LAG(SAL, 1, 0) over (order by SAL desc)
from EMP;
다음과 같이 빈 자리에 0을 집어넣고, OFFSET에 1을 집어넣은만큼 행이 1씩 계속적으로 밀리게 된다.
8. RANK()
RANK 함수는 순서대로 순위를 매겨주는 분석함수이다.
조건이 몇 위진지 묶어주는 그룹함수가 있고, 전체 순위를 매겨주는, 그룹함수가 아닌 것이 있다.
그룹함수의 문법은 다음과 같다.
RANK(조건)WITHIN GROUP(ORDER BY 컬럼명)
예시를 보자.
select rank('SMITH') within group (order by ename)
from EMP;
이렇게 하나의 함수로 묶어주는데, 만일 전체의 순위를 매겨주는 함수가 필요하다면 다음과 같다.
(단 이것은 그룹함수는 아님)
RANK() OVER (ORDER BY 컬럼명)
원리는 다음과 같다.
select ENAME, S1, S2, DECODE(S1,S2,NO-1,NO)
FROM(
select ENAME, SAL "S1" , LAG(SAL, 1, 0) over (order by SAL desc) "S2",
ROWNUM "NO"
from
(
select ENAME, SAL
from EMP
order by SAL DESC
));
먼저 내부의 빨간 쿼리에서 이름과 급여를 추출하고, 그 표를 급여의 내림차순으로 출력한다.
내부 표에서 내림차순으로 출력되었기 때문에 ROWNUM 역시 내림차순으로 정렬될 것이다. LAG 함수를 통해 S2 데이터는 하나 더 물러나게 된다.
마지막 쿼리에서는 DECODE를 통해 S1이 S2와 같으면 NO-1를, 다르면 NO를 출력한다.
결과는 다음과 같다.

S1(급여순서) 대로 순위가 매겨진 것을 확인할 수 있다.
그러나 서브쿼리는 SELECT가 많기 때문에, 많으면 많아질수록 연산이 느려질 수 있다. 따라서, SELECT를 하나만 쓰는 분석함수를 사용한다.
예시를 보자.
select NAME, height, rank() over(order by HEIGHT desc)
from STUDENT;
단순한 함수로 추출되는 것이 보인다. 그러나 이렇게 겹치는 값이 있을 수 있는데, 이것을 하나로 취급하여 연속적인 값을 출력하는, DENSE_RANK 라는 함수가 있다.
RANK, DENSE_RANK,ROWNUM을 비교해보자.
SELECT ENAME,SAL,RANK()OVER(ORDER BY SAL DESC),DENSE_RANK()OVER(ORDER BY SAL DESC),ROWNUM
FROM(
SELECT ENAME,SAL
FROM EMP
ORDER BY SAL DESC
);
다음과 같이 RANK는 같은 값을 다른 함수로 취급하고, DENSE_RANK는 하나의 갑으로 취급해 바로 다음 수가 나온다. ROWNUM은 같은 값이어도 서로 고유의 값을 넣는다. 따라서 ROWNUM을 사용하는 경우가 더 많다.
앞서 말했다시피, 다음 함수는 그룹함수가 아니기 때문에 이것을 묶을 때 GROUP BY 절을 이용할 수 없다. 어떻게 해야할까?
이를 위해서 partition절을 이용한다.
SELECT NAME,GRADE,HEIGHT,RANK()over(PARTITION BY GRADE order by height desc)
from student;
group by 절을 이용할 수 없으니 partition 절을 이용해서 그룹을 나누고, 이를 내림차순으로 정리한다.
'데이터베이스' 카테고리의 다른 글
| 8. JOIN (0) | 2020.04.01 |
|---|---|
| 오라클 실습 3. 서브쿼리와 ROWNUM을 이용한 그룹화 되지 않는 함수에 그룹함수 적용하기. (0) | 2020.03.26 |
| 6. 정규식을 이용한 함수 (0) | 2020.03.26 |
| 5. 일반함수 (0) | 2020.03.25 |
| 4. 숫자 함수, 날짜 함수 (0) | 2020.03.25 |



